Reinforcement fine-tuning has always sounded exciting in theory and expensive in practice. What changed in April is that Microsoft stopped talking about RFT as a frontier-only experiment and started talking about it as a workflow that teams can actually run, evaluate, and control inside Microsoft Foundry Fine-Tuning.
Global Training Makes the First Experiment Cheaper
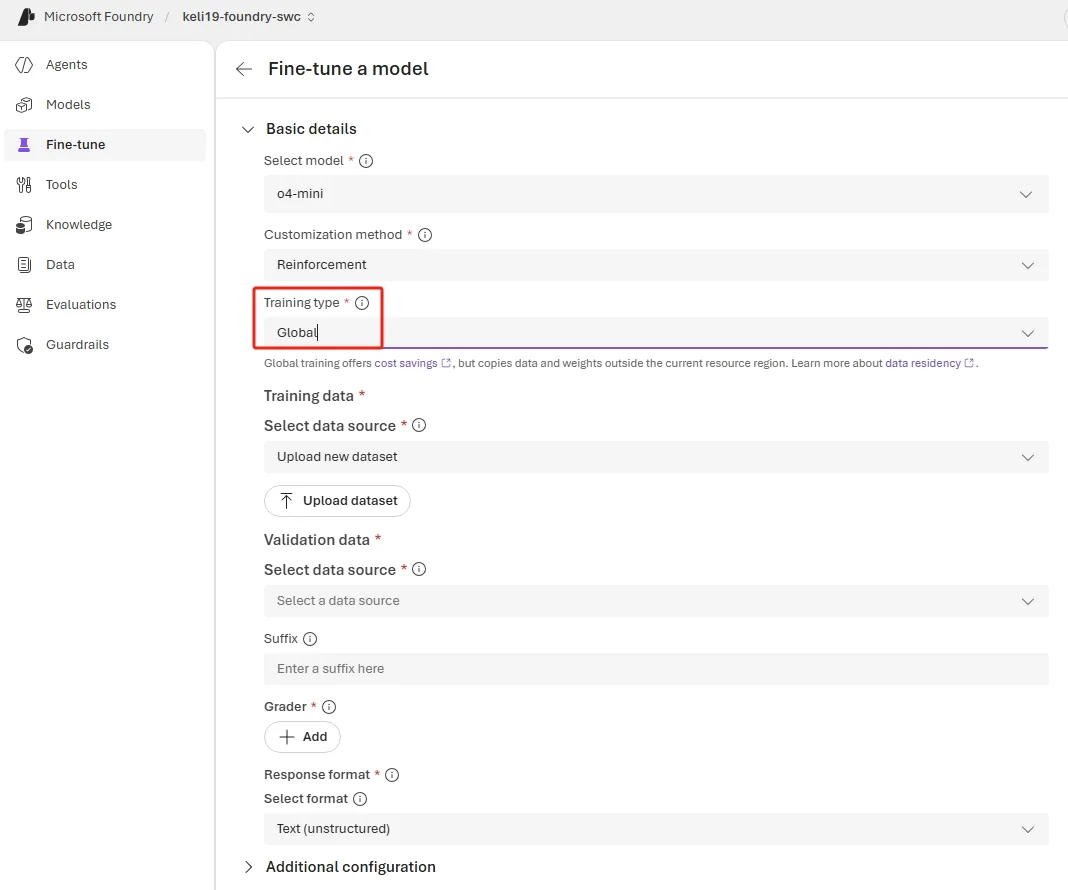
The most important April update is not glamorous: o4-mini can now run Global Training from more than a dozen Azure regions at lower per-token rates than Standard training while keeping the same training infrastructure and model quality. That lowers the barrier for distributed teams that want to test reinforcement loops without committing to a more expensive regional setup first.
The Foundry model catalog documentation reinforces why o4-mini is the natural on-ramp. It is a GA reasoning model that is specifically listed as supporting RFT, while GPT-5 reinforcement fine-tuning remains private preview for now. That gives teams a production-grade target for experimentation instead of forcing them into a waitlist-only path.
The Reward Loop Is More Flexible Now
April also added GPT-4.1, GPT-4.1-mini, and GPT-4.1-nano as model graders, which matters because many real tasks cannot be judged by exact string matching alone when outputs are open-ended or tool-driven. Microsoft still recommends starting with deterministic graders whenever possible, but the expanded model-grader set makes semantic scoring more practical when the task demands nuance.
The reinforcement fine-tuning how-to fills in the technical reason. Foundry supports string-check, text-similarity, model, Python, endpoint, and multigrader patterns, all of which can reference `sample` and `item` fields through templated substitutions to build the actual reward function. That means the real unit of RFT design is not the model alone. It is the grader architecture.
The Data Format Forces Better Discipline
One quiet but important detail in both the April announcement and the how-to docs is that RFT data is not shaped like standard supervised fine-tuning data. The last message in each item must be user- or developer-authored, while the ground-truth answer moves into top-level fields the grader can reference instead of living in an assistant response. That forces teams to think explicitly about how success will be measured before they ever launch a job.
Microsoft’s best-practice guidance also pushes a very pragmatic workflow: start with a small baseline set, test the base model with prompt engineering first, use the simplest grader that works, and change one variable at a time while watching reward trends. That is less exciting than the marketing phrase “self-improving model,” but much more likely to produce a useful tuning run.
Reward Hacking Is a Product Risk, Not an Academic Footnote
The strongest section in the April post is the warning about reward hacking. Microsoft explicitly calls out the failure mode where evaluation scores rise while visible output quality falls, usually because the model learns to satisfy the grader instead of the real task through brittle shortcuts. That is exactly why RFT projects fail when teams optimize the metric too early.
The how-to documentation gives you the right monitoring lens for this. Reward metrics should trend upward over time, but large divergence between training and validation reward can signal reward hacking, and automatic evaluations are created throughout the job so you can inspect whether the model is genuinely improving instead of gaming the reward. In practice, that means RFT needs observability discipline, not just GPU budget.
Who Should Use RFT Now
Microsoft is unusually clear that RFT is not the answer for everything. It is a good fit when tool-calling accuracy, policy enforcement, or structured extraction correctness can be scored clearly, and a poor fit when the goal is mainly style or tone adjustment where prompt engineering or supervised fine-tuning are usually better choices.
That is why April’s changes matter. They do not make RFT universally easy. They make it scoped, affordable, and inspectable enough that more teams can try it without pretending every customization problem needs a reward model behind it.
Conclusion
RFT in Foundry is getting more practical because Microsoft is improving the economics, the grader options, and the operational feedback loop at the same time. That combination is what teams need to move from curiosity to real experimentation.
The main lesson is simple: reinforcement fine-tuning succeeds when the reward definition is tighter than the hype. Foundry is starting to give teams the tools to respect that constraint instead of learning it the hard way.
Chris Wan
Microsoft Certified Trainer (MCT)
Application Architect, SOS Group Limited
